Sparse vs Dense Retrieval: Why Your Search Doesn't Understand Synonyms
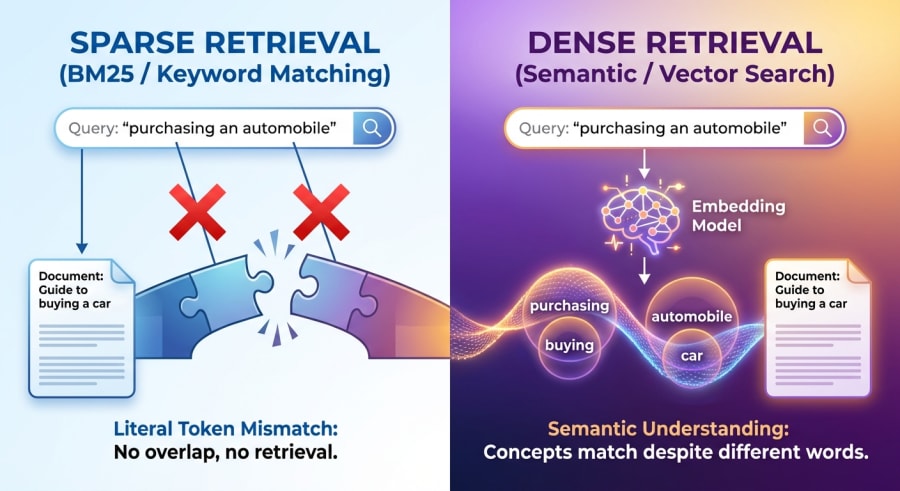
Search is one of those things we take for granted. You type “purchasing an automobile” into a system and it returns nothing, even though there’s a perfectly relevant document titled “Complete guide to buying a car from a dealership” sitting right there. The words are different, but the meaning is identical. So what went wrong?
It comes down to how retrieval systems represent and match text. Two fundamentally different paradigms are at play: sparse retrieval (keyword matching) and dense retrieval (semantic search). The difference between them determines whether your RAG pipeline actually works or quietly fails on every synonym, paraphrase, and colloquial variation your users throw at it.
The Keyword Matching Problem
Traditional search engines (and many retrieval systems still running in production) rely on keyword matching. The most well-known algorithm in this family is BM25 (Best Matching 25), a ranking function rooted in term frequency and inverse document frequency. It’s fast, interpretable, and has been the backbone of information retrieval for decades.
BM25 asks a simple question: how many of the query’s terms appear in a given document, and how rare are those terms across the entire corpus? A document containing multiple instances of an uncommon query term scores higher. Two tuning parameters, k1 for term frequency saturation and b for document length normalisation, control how aggressively it rewards repetition and penalises verbose documents.
The problem? BM25 is ruthlessly literal. It operates on exact token overlap. The word “car” and the word “automobile” share zero characters, so from BM25’s perspective, they’ve got nothing in common. A query for “buying a car” will rank a document about car shopping highly, while a document about “purchasing an automobile” (semantically identical) may score poorly or not at all.
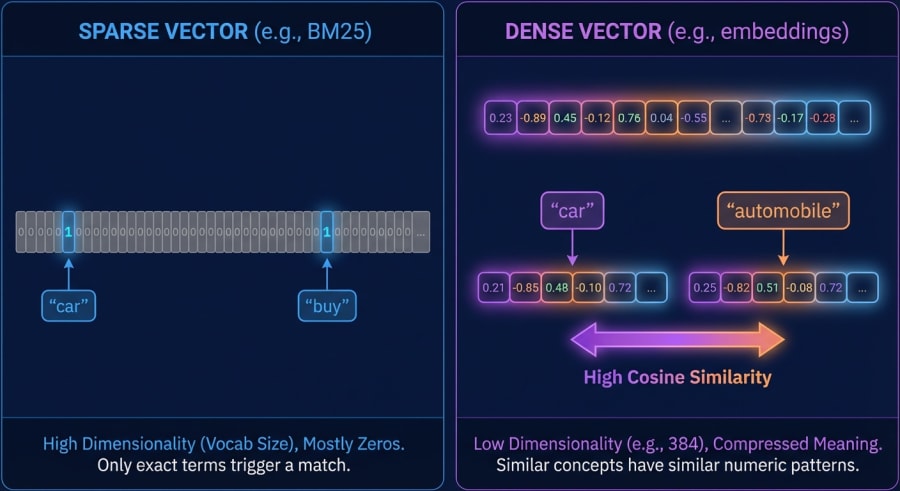
That’s not a bug. It’s a fundamental limitation of sparse representations. In a BM25 system, each document is represented as a sparse vector where dimensions correspond to vocabulary terms. If a term doesn’t appear, that dimension is zero. Two documents about the same topic using different words produce vectors with little to no overlap.
Enter Dense Vector Search
Dense retrieval flips this entirely. Instead of matching on individual words, it transforms both queries and documents into dense numerical vectors, compact arrays of floating-point numbers that encode semantic meaning. These vectors live in a continuous embedding space where proximity corresponds to conceptual similarity.
The real work happens in the embedding model. A model like all-MiniLM-L6-v2 compresses text into 384-dimensional vectors. During training, the model learns that “buy,” “purchase,” and “acquire” cluster together in this space, as do “car,” “automobile,” and “vehicle.” When you compute the cosine similarity between the vectors for “buying a car” and “purchasing an automobile,” the score is high, because the model understands they mean the same thing.
That’s the core insight: dense retrieval captures meaning beyond surface-level word overlap. It handles synonyms, paraphrases, and even conceptual relationships that keyword matching simply can’t.
Building a Side-by-Side Comparison
To make this concrete, I put together a demonstration using LlamaIndex that runs both retrieval strategies against the same document corpus and the same queries. A small collection of documents about car buying, with one deliberate outlier thrown in:
const documents = [
new Document({ text: 'Complete guide to buying a car from a dealership' }),
new Document({ text: 'How to purchase an automobile: step by step process' }),
new Document({ text: 'Tips for acquiring a new vehicle on a budget' }),
new Document({ text: 'Best practices for car shopping and negotiation' }),
new Document({ text: 'Bicycle maintenance and repair tutorials' }),
new Document({ text: 'Selling your old car for the best price' }),
];Notice the intentional vocabulary variation. Documents 1 to 3 all describe essentially the same concept (obtaining a car) but use different words: “buying,” “purchase,” “acquiring,” and “car,” “automobile,” “vehicle.” Document 5 is the control, completely off-topic, about bicycles.
The embedding model is configured using HuggingFace’s quantised all-MiniLM-L6-v2, which gives us a good balance of speed and quality:
Settings.embedModel = new HuggingFaceEmbedding({
modelType: 'Xenova/all-MiniLM-L6-v2',
quantized: true,
});From a single index, we create both retrievers. The BM25 retriever operates on the document store directly, while the dense retriever uses the vector embeddings generated during indexing:
const index = await VectorStoreIndex.fromDocuments(documents);
const bm25Retriever = new Bm25Retriever({
docStore: index.docStore,
topK: 6,
});
const denseRetriever = index.asRetriever({
similarityTopK: 6,
});Both retrievers get the same topK of 6, meaning they return all documents ranked by relevance. Same corpus, same queries, different retrieval logic.
The Revealing Query Pair
The real test comes from running two semantically identical queries: "buying a car" and "purchasing an automobile". These mean the same thing to any human reader, but they share no significant keywords.
const queries = ['buying a car', 'purchasing an automobile'];
for (const query of queries) {
const bm25Response = await bm25Retriever.retrieve({ query });
const denseResponse = await denseRetriever.retrieve(query);
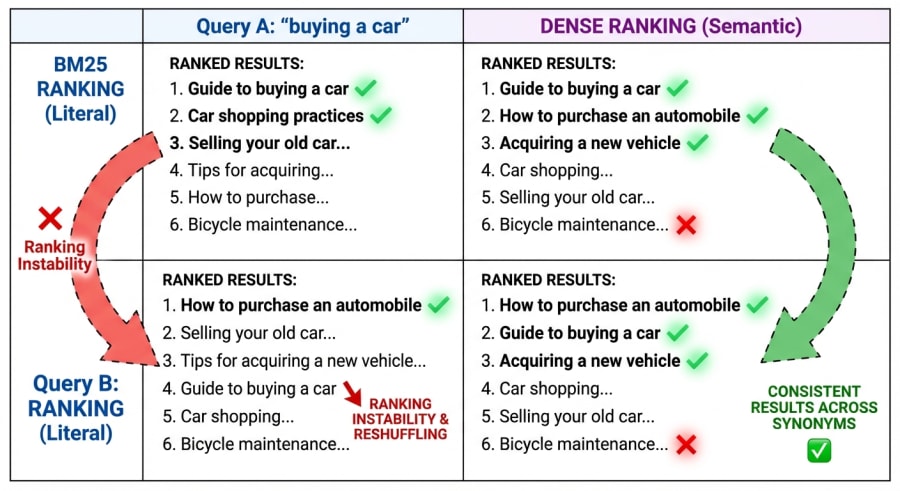
}With BM25, the results shift dramatically between the two queries. “Buying a car” lights up documents containing those exact words: the guide to buying a car, car shopping practices. But “purchasing an automobile” reshuffles the rankings entirely, now favouring the document about purchasing an automobile while the previously top-ranked car buying guide drops. The algorithm found a different set of matching tokens and produced a different ranking. Same intent, different results.
Dense vector search tells a different story. Both queries produce nearly identical rankings. The embedding model recognises that buying equals purchasing and car equals automobile, so the top results stay stable regardless of which synonym the user happens to choose. The car buying guide, the automobile purchasing guide, and the vehicle acquisition tips all cluster tightly together with high similarity scores. Meanwhile, the bicycle maintenance document consistently scores low (as it should).
Here’s sample output showing both retrieval methods side by side. Hit Run to watch it play through:
Why This Matters for RAG
In a Retrieval-Augmented Generation pipeline, the retriever is the gatekeeper. The LLM can only reason over documents that the retriever surfaces. If your retriever misses a relevant document because the user phrased their question differently than the document’s author wrote the content, the LLM generates an answer with incomplete context. It doesn’t hallucinate because it’s confused. It hallucinates because it never saw the right information.
Dense retrieval becomes essential here. Real users don’t know (or care) what exact terminology your documents use. They search naturally, using whatever words come to mind. A system that breaks when faced with “automobile” instead of “car” isn’t ready for production.
That said, BM25 has real strengths. Keyword matching excels at precision when exact terms matter: product codes, proper nouns, technical jargon that shouldn’t be semantically softened. A search for “BMW 320i” should match documents with that exact string, not drift toward “luxury sedan.” BM25 is also fast, requires no GPU, and needs no model training.
The Hybrid Path Forward
The most effective production systems don’t choose between sparse and dense. They combine both. Hybrid retrieval pipelines run BM25 and dense search in parallel, then merge results using reciprocal rank fusion or learned score combination. This captures exact keyword matches where they matter while still surfacing semantically relevant documents that keyword search would miss.
LlamaIndex supports this pattern directly. The same VectorStoreIndex that powers our dense retriever also exposes its document store for BM25. You can build both retrievers from a single index and fuse their results at query time.
The bottom line: if your retrieval system treats “car” and “automobile” as unrelated concepts, you’ve got a sparse retrieval problem. Dense embeddings solve it by encoding meaning rather than matching characters. But the best systems layer both approaches, using keyword precision where it counts and semantic understanding everywhere else.
Getting this distinction right (and knowing when each approach shines) is the difference between a retrieval pipeline that works on curated demos and one that holds up against the messy, unpredictable language of real users.